Datasets
Multimedia Fact Checking Datasets
MUSMA offers a comprehensive overview of datasets for automatic fact-checking, with a special focus on multimodal resources (text + images/videos). You’ll find comparative views, charts, and summaries to visually contrast sources, characteristics, and annotation methodologies across 39+ curated datasets.
Our goal is to provide a practical tool for researchers and practitioners to understand dataset peculiarities and current challenges (e.g., bias, representativeness, access constraints).
What you will find here
- High-level comparison across datasets (availability, licensing, modality, scale).
- Task-oriented view (claim detection, verification, stance, evidence retrieval, multimodal fusion, etc.).
- Per-dataset deep dives with metadata, splits, sources, and caveats.
- Notes on ethical compliance, data integrity, and reproducibility.
All information is based on our survey [Gallegos26] and GitHub repository.
Quick comparison with other surveys
Dataset information
| Dataset | Year | Topics | Languages | # Samples |
|---|---|---|---|---|
| FakeClaim | 2024 | 2023 Israel-Hamas War | 30 languages | 755 |
| FineFake | 2024 | Various (incl. Politics, Health, Conflicts) | EN | 16,909 |
| WarClaim | 2024 | 2023 Israel-Hamas War | 40 languages | 2,773 |
| RD-E | 2024 | Various (incl. Politics, Health, COVID19) | EN | 32,892 |
| MR2 | 2023 | Various (incl. Politics, Health) | EN ZH | 14,700 |
| Factify2 | 2023 | Various (USA and Indian Politics) | EN | 50,000 |
| MOCHEG | 2023 | Various | EN | 15,601 |
| OcCMMFC | 2022 | Various | EN | 85,360 |
| STVD-FC | 2022 | 2022 French Presidential Election | FR | 1,200 |
| Factify | 2022 | Various (USA and Indian Politics, Health) | EN | 50,000 |
| MuMiN | 2022 | Various | 41 languages | 12,914 |
| PolitifactSnopes | 2020 | Politics | EN | 13,239 |
| Fauxtography | 2019 | Various | EN | 1,305 |
| ChileCP | 2025 | Chile’s constitutional process | ES | 300 |
| VERITE | 2024 | Various | EN | 1,000 |
| CHASMA | 2024 | Various | EN | 2,015,488 |
| CHASMA-D | 2024 | Various | EN | 291,782 |
| MFD-Task1 | 2023 | 2022 Ukrainian-Russian war | IT | 1,795 |
| MFD-Task2 | 2023 | 2022 Ukrainian-Russian war | IT | 1,460 |
| CLIP-NESt | 2023 | Various (incl. Politics, Environment, Law) | EN | 2,838,082 |
| COSMOS | 2023 | Various (incl. Politics, Health, Environment) | EN | 200,000 + 1,700 |
| Twitter-COMMs | 2022 | COVID19, Climate, Military Vehicles | EN | 2,468,592 |
| Evons | 2022 | 2016 USA Presidential Election | EN | 92,969 |
| CovID I | 2022 | COVID19 | EN | 2,369 |
| CovID II | 2022 | COVID19 | EN | 2,474 |
| COVID5G | 2022 | COVID19 5G Conspiracy Theories | EN | 6,000 |
| NewsCLIPpings | 2021 | Various | EN | 988,283 |
| VOA-KG2txt | 2021 | Various | EN | 30,000 |
| Weibo C | 2021 | Various | ZH | 10,130 |
| NeuralNews | 2020 | Various | EN | 128,000 |
| TamperedNews | 2020 | Various | EN | 1,079,523 |
| News400 | 2020 | Various (incl. Politics, Economy, Sports) | DE | 6,360 |
| ReCOVery | 2020 | COVID19 | 40 languages | 2,029 + 140,820 |
| r/Fakeddit | 2020 | Various | EN | 1,063,106 |
| FakeNewsNet | 2020 | Politics, Entertainment | EN | 23,196 |
| ExFaux | 2020 | Various | EN | 263 |
| NewsBag | 2020 | Various | EN | 215,000 |
| NewsBag++ | 2020 | Various | EN | 589,000 |
| NewsBag Test | 2020 | Various | EN | 29,000 |
We reviewed 39 recent datasets commonly used in multimodal fact-checking and automated fact verification, spanning text, images, videos, and social media content. Together, they provide a snapshot of the current research landscape, its strengths, but also its structural gaps.
A first, striking observation is the dominance of English-language datasets. While this reflects English’s role as the lingua franca of science and online news, it also exposes a critical limitation: most fact-checking approaches remain strongly language-dependent. As a result, models trained on these datasets risk limited applicability when deployed in non-English-speaking contexts.
Multilingual datasets do exist, but they remain few in number and relatively small in scale compared to their English counterparts. Moreover, many of them are event-specific (e.g., conflicts, elections, pandemics), which constrains their generalization across topics and cultural settings. Languages beyond English are often underrepresented, both in terms of sample size and topical diversity.
Another key trend is the high variability in dataset scale and scope. Some resources contain only a few hundred annotated samples, while others include millions of instances, often collected with different assumptions, annotation strategies, and evidence types. This heterogeneity makes direct comparison between models challenging and highlights the importance of dataset-aware evaluation.
Overall, this analysis underscores a pressing need for more diverse, multilingual, and culturally inclusive datasets, as well as clearer documentation of dataset biases and limitations. Addressing these gaps is essential to ensure that multimodal fact-checking research can scale beyond English-centric and event-driven scenarios, and better reflect the global nature of online information ecosystems.
Key Takeaways
- English-centric by design 🌍
Most datasets are English-only; multilingual resources exist but are smaller, event-specific, and hard to generalize. - From tiny to massive 📊
Dataset sizes vary by orders of magnitude (from hundreds to millions of samples) shaping what models can realistically learn. - Bias is the norm, not the exception ⚠️
Topic focus, language imbalance, and annotation choices strongly affect evaluation and real-world reliability.
Tasks and labeling schemes
| Dataset | ✔️ FAC | 🧩 INC | 🔍 STA | 📝 EXP | 📚 RET | # Labels |
|---|---|---|---|---|---|---|
| FakeClaim | 🟢 | 🟢 | 2 | |||
| FineFake | 🟢 | 🟢 | 2 or 6 | |||
| WarClaim | 🟢 | 1 | ||||
| RD-E | 🟢 | 6 | ||||
| MR2 | 🟢 | 3 | ||||
| Factify2 | 🟢 | 🟢 | 5 | |||
| MOCHEG | 🟢 | 🟢 | 🟢 | 3 | ||
| OcCMMFC | 🟢 | 2 | ||||
| STVD-FC | 🟢 | 3 | ||||
| Factify | 🟢 | 🟢 | 5 | |||
| MuMiN | 🟢 | 2 | ||||
| PolitifactSnopes | 🟢 | 🟢 | 1 or 2 | |||
| Fauxtography | 🟢 | 🟢 | 2 | |||
| ChileCP | 🟢 | 3 | ||||
| VERITE | 🟢 | 2 or 3 | ||||
| CHASMA | 🟢 | 2 | ||||
| CHASMA-D | 🟢 | 2 | ||||
| MFD-Task1 | 🟢 | 3 | ||||
| MFD-Task2 | 🟢 | 4 | ||||
| CLIP-NESt | 🟢 | 3 | ||||
| COSMOS | 🟢 | 🟢 | 2 | |||
| Twitter-COMMs | 🟢 | 2 | ||||
| Evons | 🟢 | 2 | ||||
| CovID I | 🟢 | 2 | ||||
| CovID II | 🟢 | 2 | ||||
| COVID5G | 🟢 | 🟢 | 3 or 5 or 6 | |||
| NewsCLIPpings | 🟢 | 2 | ||||
| VOA-KG2txt | 🟢 | 🟢 | 2 | |||
| Weibo C | 🟢 | 2 | ||||
| NeuralNews | 🟢 | 2 or 4 | ||||
| TamperedNews | 🟢 | 2 | ||||
| News400 | 🟢 | 2 | ||||
| ReCOVery | 🟢 | 2 | ||||
| r/Fakeddit | 🟢 | 🟢 | 2 or 3 or 6 | |||
| FakeNewsNet | 🟢 | 2 | ||||
| ExFaux | 🟢 | 2 or 5 | ||||
| NewsBag | 🟢 | 2 | ||||
| NewsBag++ | 🟢 | 2 | ||||
| NewsBag Test | 🟢 | 2 |
Multimodal fact-checking datasets support different research tasks, ranging from detecting false claims to identifying inconsistencies between text and multimedia content. They also adopt diverse labeling strategies, from simple true/false decisions to multi-class annotations capturing uncertainty and content relationships.
What tasks do datasets support?
- Fact Verification (FAC) ✔️
Determine whether a claim is true or false. This is the most common task across datasets. - Cross-modal Inconsistency Detection (INC) 🧩
Identify mismatches between text and multimedia content (e.g., misleading captions or out-of-context images). - Stance / Evidence Relation (STA) 🔍
Assess whether available evidence supports, refutes, or is unrelated to a claim. - Explanation Generation (EXP) 📝
Produce human-readable justifications for fact-checking decisions. - Evidence Retrieval (RET) 📚
Retrieve relevant documents or sources to support the verification process.
Labeling Insights
- Binary labels dominate (e.g., Real vs Fake), especially in claim-only datasets.
- Multi-class annotations capture nuance, such as uncertainty (Not Enough Information) or different types of manipulation.
- Granularity varies widely, allowing some datasets to support both coarse and fine-grained analysis.
Key Takeaways
- Fact-checking remains the dominant task
Most datasets focus on verifying whether a claim is true or false, often with optional supporting evidence. - Multimodal inconsistency detection is rapidly growing
Many newer datasets specifically target misleading combinations of text, images, or videos (e.g., miscaptioning or out-of-context media). - Labeling granularity varies widely
While many datasets use binary annotations, others include uncertainty-aware labels (e.g., unverified or not enough information) or fine-grained misinformation categories.
Multimedia coverage across datasets
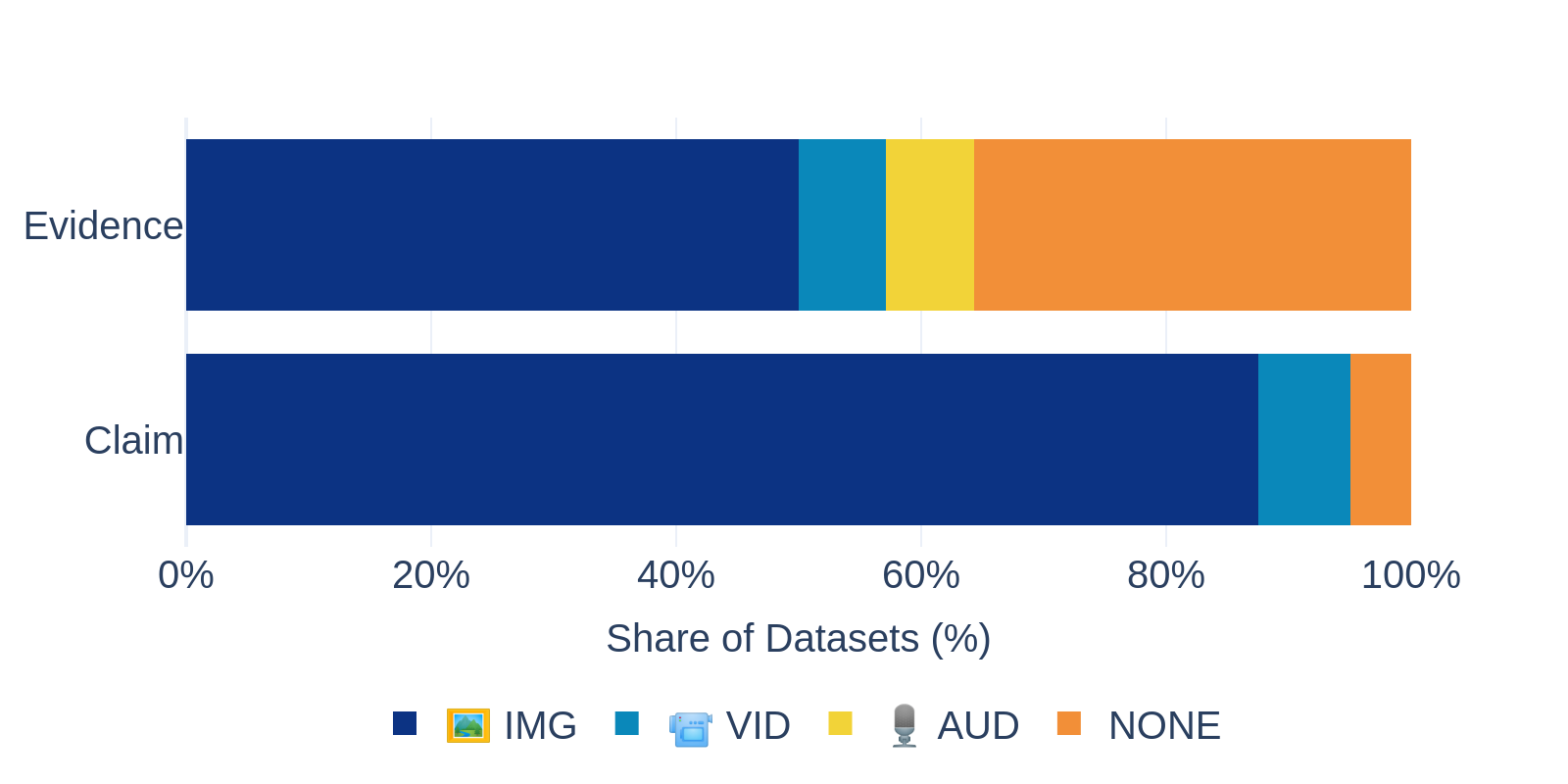
Most multimodal fact-checking datasets are still image-centric, especially when multimedia appears in the claim itself. Video and audio remain marginal, and evidence is often text-only.
- Images dominate 🖼️ claims, while videos and audio are still rare.
- Evidence is less multimodal than claims, often relying on text even when claims include media.
- Audio is largely unexplored 🎙️, highlighting a clear gap for future datasets and models.
Where does the data come from?
The origin of claims, evidence, and labels strongly shapes how fact-checking models behave. Across datasets, sources range from real-world social media posts to automatically generated content and expert fact-checking platforms.
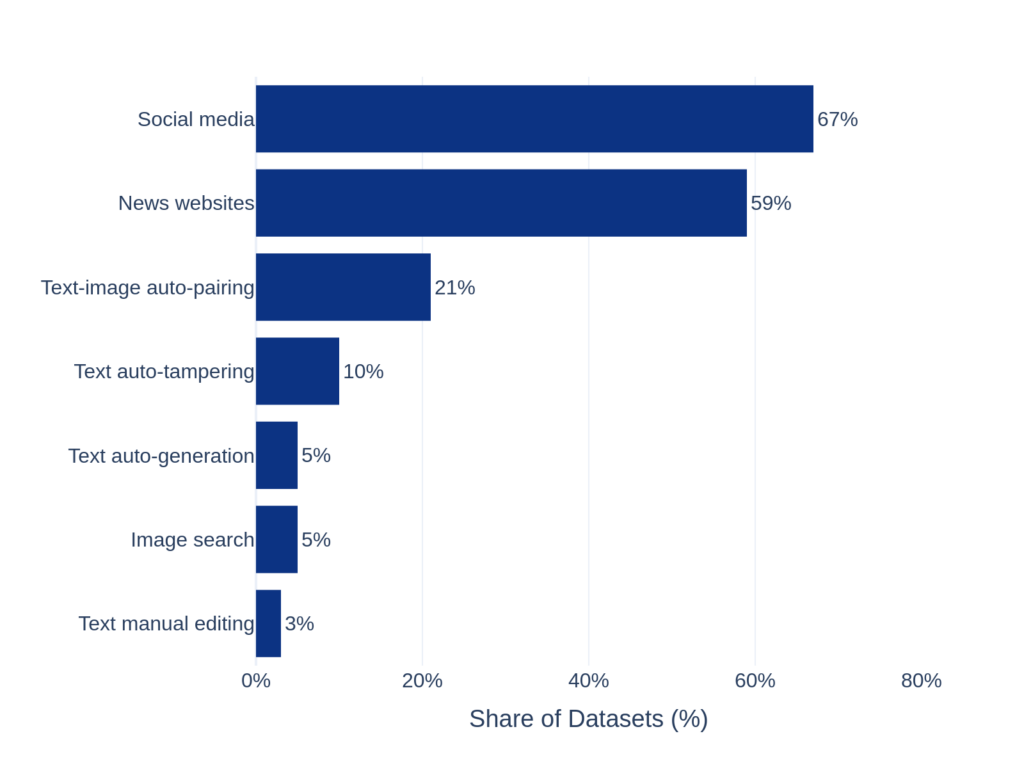
Claim sources
- Social media dominates (67%), with platforms like X (Twitter), Reddit, Facebook, YouTube, TikTok, Instagram, Weibo, Telegram, and WhatsApp.
- News websites are also common (59%), often used alongside social media content.
- A smaller share of datasets rely on synthetic or constructed claims, including auto-generated text, text tampering, or automatic text–image pairing.
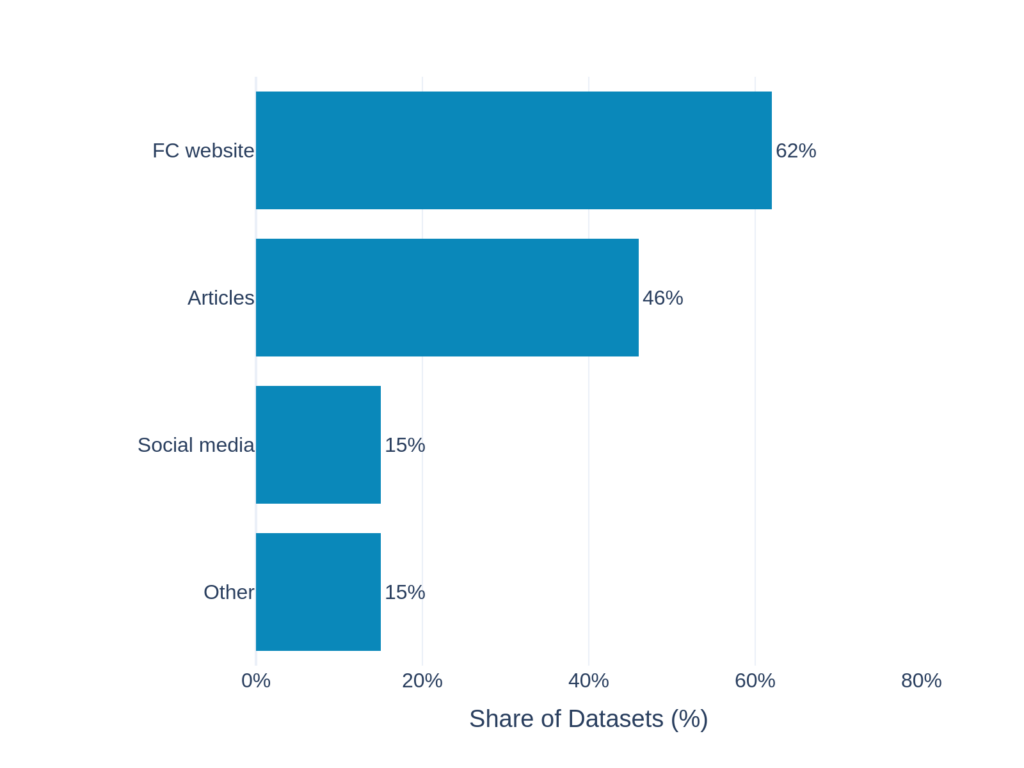
Evidence sources
- Fact-checking websites are the primary source of evidence (62%), reflecting their central role in verification workflows.
- Some datasets automatically retrieve web articles via search engines, explicitly filtering out fact-checking sites to avoid bias or information leakage.
- Social media is only rarely used as evidence.
Label sources
- Labels come from fact-checking organizations and human annotation, but
- 41% of datasets assign labels “by construction”, meaning truthfulness is implied by how the data was created rather than independently verified.

Key Takeaways
Claims are predominantly sourced from social media, while evidences and labels largely originate from fact-checking websites or are assigned by construction. A design choice that may introduce information leakage and should be considered during evaluation.
⚠️ A note on information leakage
When claims, evidence, and labels are all sourced from fact-checking websites, information leakage can occur, potentially inflating model performance. Some datasets exhibit verified leakage (‼️), while others present possible leakage (❓) due to unclear or partial data collection procedures. Users should keep this in mind when training and evaluating models.
| Dataset | Information leakage |
|---|---|
| FakeClaim | ‼️ |
| FineFake | 🟢 |
| WarClaim | ‼️ |
| RD-E | ❓ |
| MR2 | ❓ |
| Factify2 | ‼️ |
| MOCHEG | 🟢 |
| OcCMMFC | ❓ |
| STVD-FC | 🟢 |
| Factify | ‼️ |
| MuMiN | ‼️ |
| PolitifactSnopes | ‼️ |
| Fauxtography | ❓ |
| ChileCP | ‼️ |
How accessible are multimodal fact-checking datasets?
Most datasets are nominally public, but actual usability varies widely. While text data is often easy to share, multimedia content (images, videos) introduces practical, legal, and technical constraints that directly affect reproducibility.
- Fully downloadable datasets 🟢 are the exception, not the rule. A small subset provides both text and images via direct downloads or author-hosted repositories.
- Partial access is common 💬. Many datasets release text only, while images or videos are shared as links, require author requests, or depend on external platforms.
- Reproducibility barriers persist ⚙️🅰️. Synthetic datasets require running code pipelines, and API-based datasets depend on costly or restricted services (e.g. Twitter/X, YouTube).
- Some datasets are effectively unaccessible ❌. Despite being cited in the literature, they are no longer publicly accessible or recoverable.
Together, these factors highlight a key challenge for the field: open datasets are common, but fully usable multimodal datasets are still rare.
Dataset Availability
Legend:
- 🟢 Direct download: most data immediately available
- 💬 On request: requires contacting authors
- ⚙️ Code-generated: full dataset obtained by running scripts
- 🅰️ API-based: access depends on external platforms
- ❌ Unavailable: not publicly accessible

Distribution of dataset availability types. Percentages exceed 100% because datasets may rely on multiple access mechanisms.
Text-image consistency in multimodal content
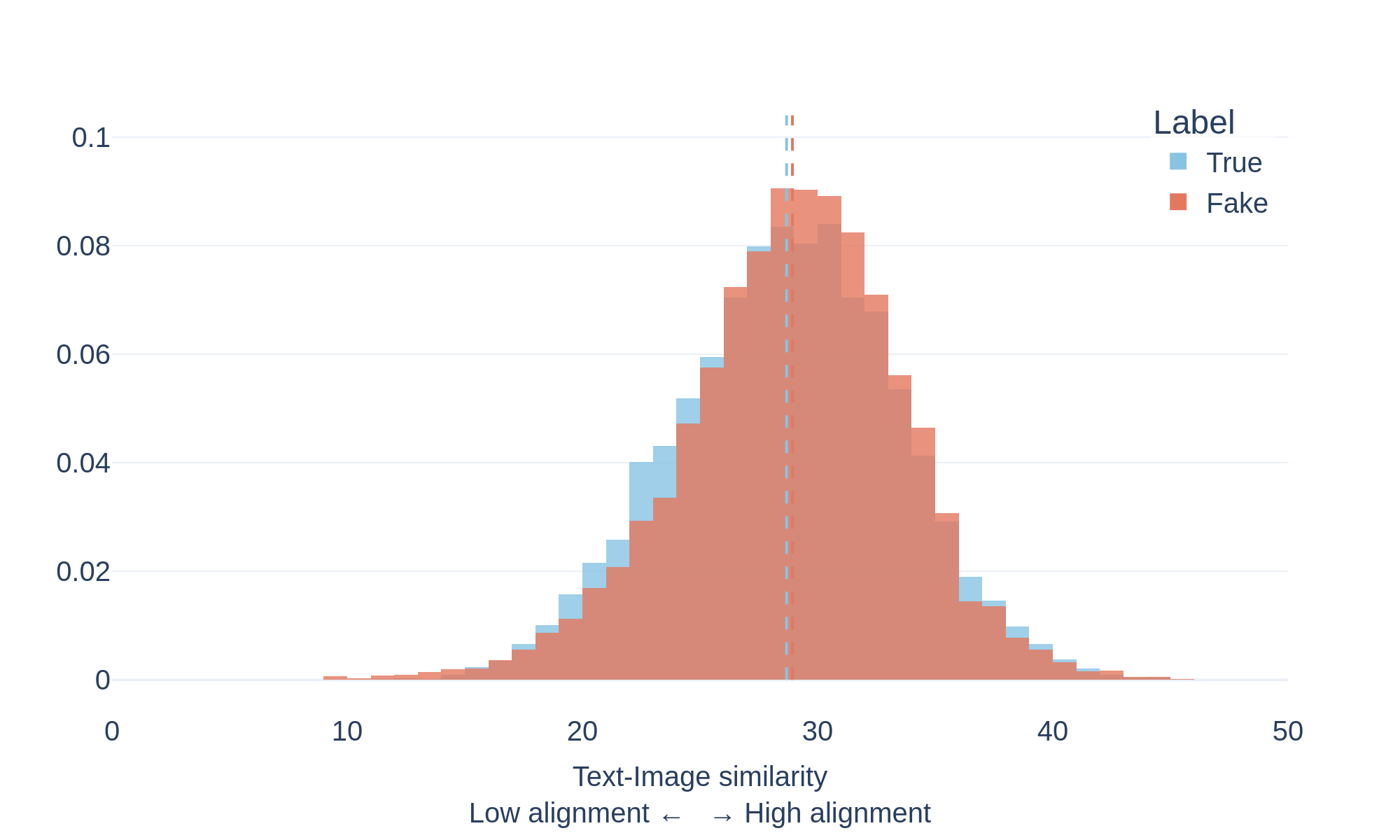
Many online posts combine text and images to communicate information. In reliable content, these two modalities typically reinforce the same message. In misleading or manipulated content, however, images and text may be loosely related or intentionally mismatched.
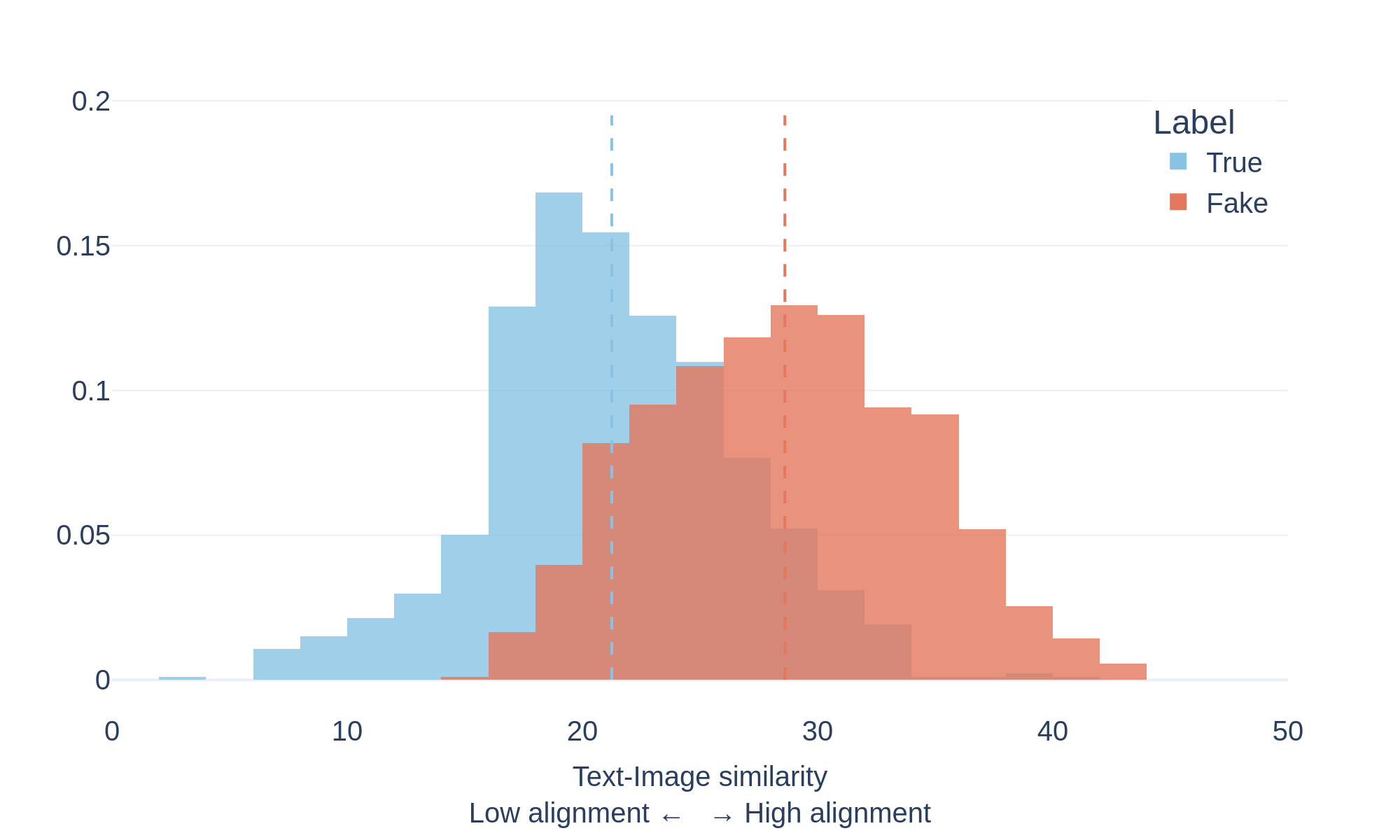
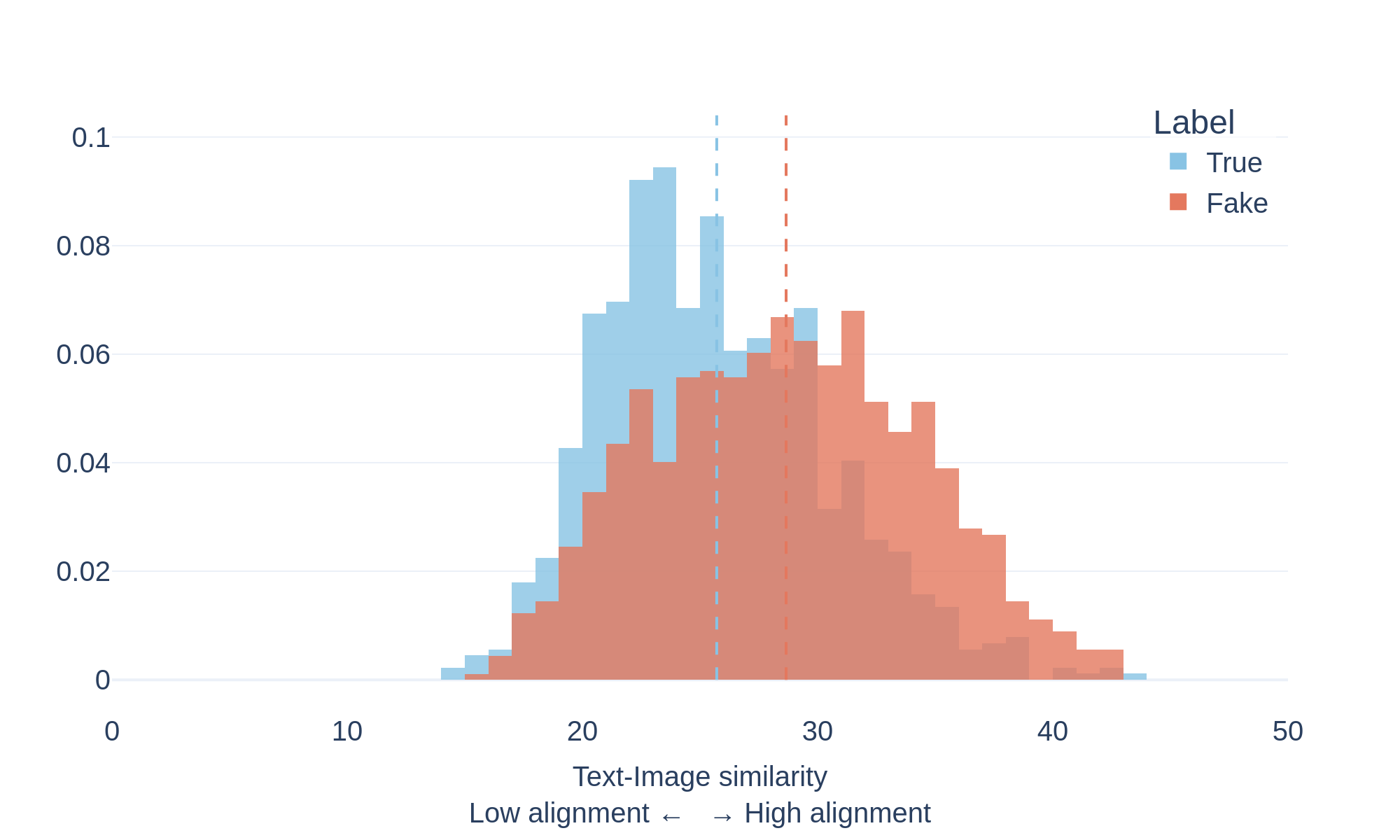
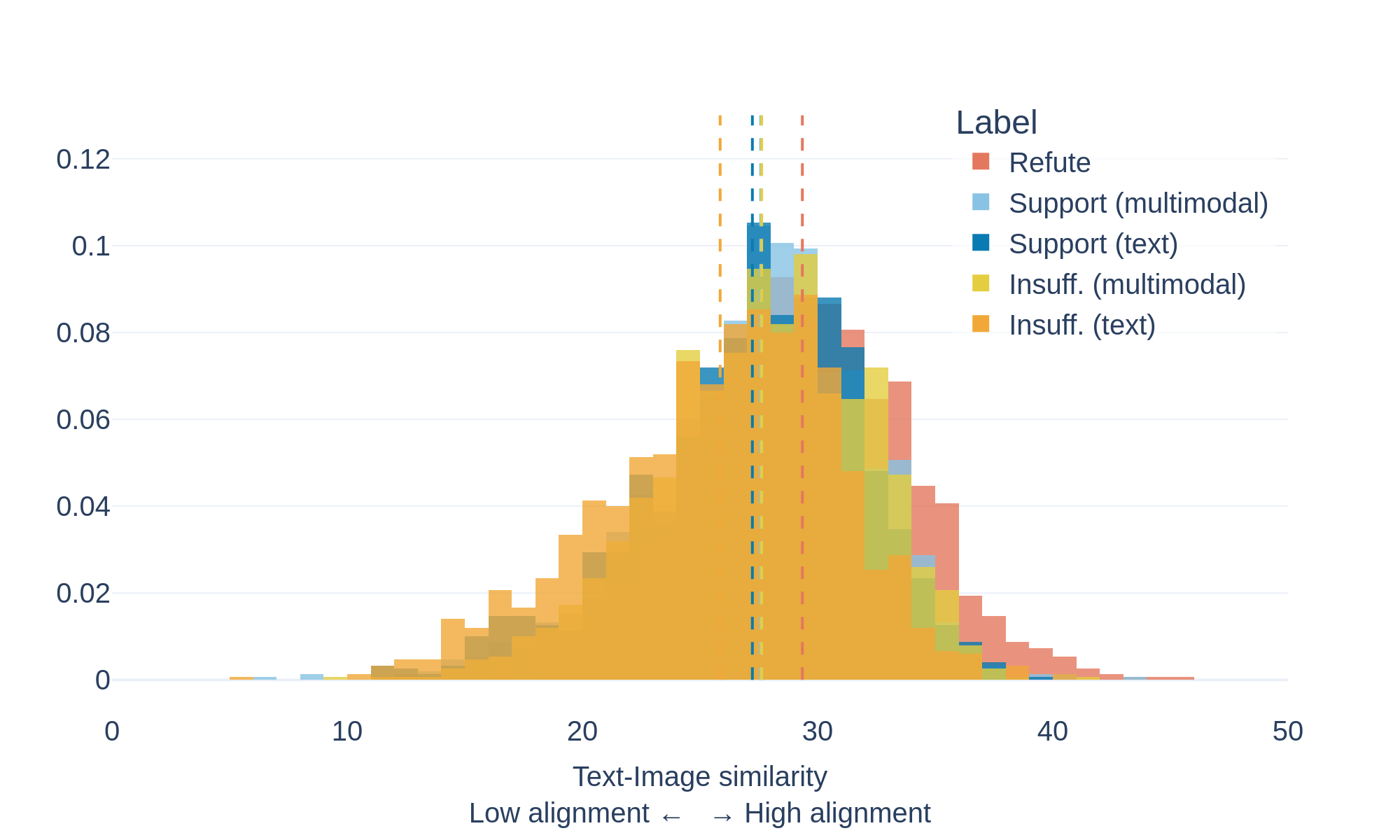
To study this phenomenon, we measure the semantic similarity between text and images using a vision–language model (CLIP). The model encodes both modalities in a shared representation space and computes a similarity score indicating how closely the image content matches the accompanying text.
The plots above show the distribution of text-image similarity scores for documents labeled as true and fake within the evaluated datasets.
What the distributions show
The distributions reveal an interesting pattern:
- 🔴 Fake documents tend to exhibit higher text–image similarity scores.
- 🔵 True documents show a broader distribution with generally lower scores.
This suggests that misleading content often pairs text with images that strongly reinforce the narrative being presented, even when the underlying claim may be inaccurate or misleading.
By contrast, reliable sources frequently use illustrative or symbolic imagery that may not directly match the exact textual description.
These results highlight that strong visual-text alignment does not necessarily indicate factual accuracy, and that multimodal misinformation can leverage highly coherent visual narratives to increase credibility.
CovID I
CovID II
Factify2
r/Fakeddit
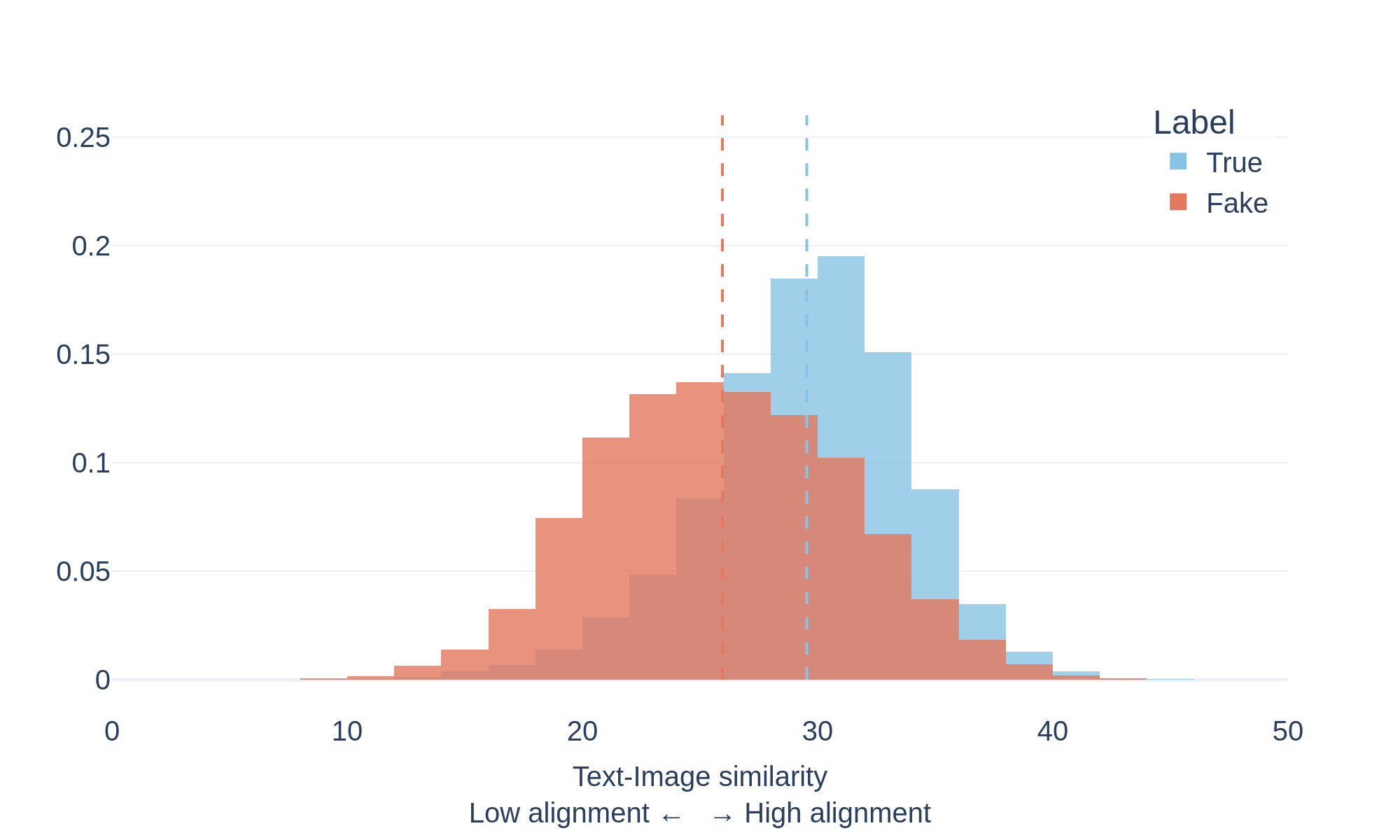
ReCOVery
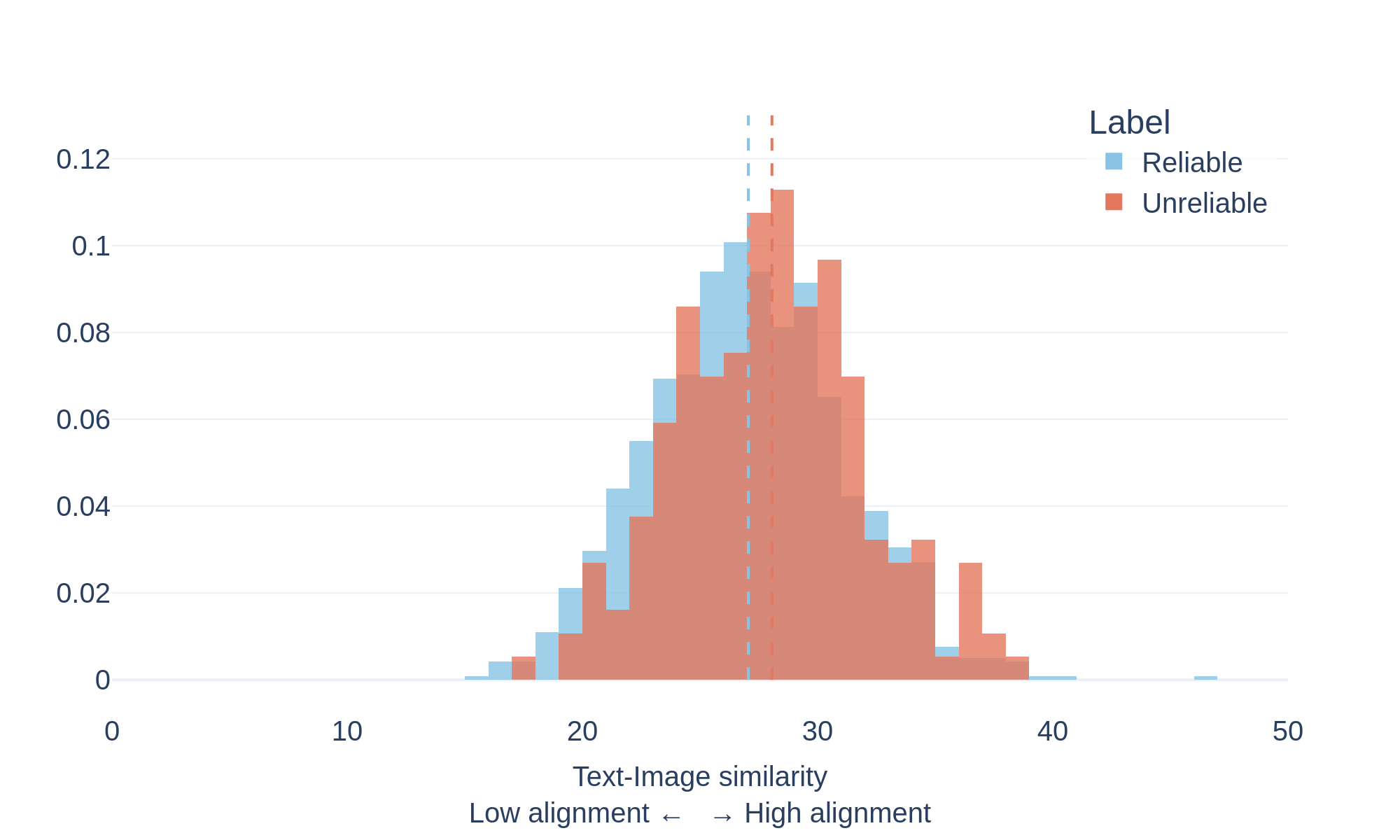
FineFake
Complete comparison
| Dataset | Year | Topic | Languages | # Samples | Claim multimedia type | Evidence multimedia type | Task | # Labels | # Labels | Claim origin | Evidence origin | Label origin | Information leakage | Availability | Link |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FakeClaim | 2024 | 2023 Israel-Hamas War | 30 languages | 755 | 📹 | FAC, STA | 2 | 2: Real, Fake | Social media | FC website | FC websites | ‼️ | 🅰️ ⚙️ | https://github.com/Gautamshahi/FakeClaim | |
| FineFake | 2024 | Various (incl. Politics, Health, Conflicts) | EN | 16,909 | 🖼️ | FAC, INC | 2 or 6 | 2: Real, Fake 6: real, text-image inconsistency, content-knowledge inconsistency, text-based fake, image-based fake, others | Social media, News websites | FC website | FC websites, Human annotation | 🟢 | https://drive.google.com/file/d/16D9ix7ZOisa4VVBznBTBcv1N7TA-jodH | ||
| WarClaim | 2024 | 2023 Israel-Hamas War | 40 languages | 2,773 | 🖼️📹 | FAC | 1 | 1: False | Social media | FC website | FC websites | ‼️ | 🅰️ ⚙️ | https://github.com/Gautamshahi/WarClaim/ | |
| RD-E | 2024 | Various (incl. Politics, Health, COVID19) | EN | 32,892 | 🖼️⁕ | FAC | 6 | 6: true, mostly true, half true, mostly false, false, pants on fire | Social media | FC website, Other | FC websites | ❓ | 💬 | https://github.com/zhengyang5/RDE | |
| MR2 | 2023 | Various (incl. Politics, Health) | EN ZH | 14,700 | 🖼️ | 🖼️ | FAC | 3 | 3: Rumor, Non-Rumor, Unverified | Social media | Articles | FC websites, Human annotation | ❓ | 🟢 | https://github.com/THU-BPM/MR2 |
| Factify2 | 2023 | Various (USA and Indian Politics) | EN | 50,000 | 🖼️ | 🖼️ | FAC, STA | 5 | 5: Support_text, Support_multimodal, Insufficient_text, Insufficient_multimodal, Refute | Social media, News websites, Image search | FC website, Articles, Social media | FC websites, By construction | ‼️ | 🟢 💬 | https://aiisc.ai/defactify2/factify.html |
| MOCHEG | 2023 | Various | EN | 15,601 | 🖼️ | FAC, STA, EXP | 3 | 3: Support, Refute, NEI | Social media | Articles | FC websites | 🟢 | https://github.com/VT-NLP/Mocheg | ||
| OcCMMFC | 2022 | Various | EN | 85,360 | 🖼️ | 🖼️ | INC | 2 | 2: falsified, pristine | News websites | Articles | By construction | ❓ | 💬 | https://s-abdelnabi.github.io/OoC-multi-modal-fc/ |
| STVD-FC | 2022 | 2022 French Presidential Election | FR | 1,200 | 📹🎙️ | FAC | 3 | 3: False, Imprecise, True | Social media | Other | FC websites | 💬 | http://mathieu.delalandre.free.fr/projects/stvd/ | ||
| Factify | 2022 | Various (USA and Indian Politics, Health) | EN | 50,000 | 🖼️ | 🖼️ | FAC, STA | 5 | 5: Support_text, Support_multimodal, Insufficient_text, Insufficient_multimodal, Refute | Social media, Image search | FC website, Articles, Social media | FC websites, By construction | ‼️ | 🟢 💬 | https://competitions.codalab.org/competitions/35153 |
| MuMiN | 2022 | Various | 41 languages | 12,914 | 🖼️⁕ | 🖼️ | FAC | 2 | 2: Misinformation, Factual | Social media | FC website | FC websites | ‼️ | 🅰️ | https://mumin-dataset.github.io/ |
| PolitifactSnopes | 2020 | Politics | EN | 13,239 | 🖼️ | 🖼️ | RET, STA | 1 or 2 | 1: False 2: Related, not related | Social media | FC website | FC websites, Human annotation | ‼️ | 🟢 | https://github.com/nguyenvo09/EMNLP2020 |
| Fauxtography | 2019 | Various | EN | 1,305 | 🖼️ | FAC, INC | 2 | 2: True, False | Social media | Articles | FC websites | ❓ | 🟢 | https://gitlab.com/didizlatkova/fake-image-detection | |
| ChileCP | 2025 | Chile’s constitutional process | ES | 300 | 🖼️⁕ | (no evidence) | FAC | 3 | 3: True, False, Non verified/Others (the site doesn’t verify news) | News websites | FC websites | ‼️ | 🟢 | https://github.com/MolodyGs/Multimodal-News-Data-Collection | |
| VERITE | 2024 | Various | EN | 1,000 | 🖼️ | (no evidence) | INC | 2 or 3 | 2: True, Misinformation 3: True, OOC (text and img are true, but ooc), MC (Miscaptioned: fake text) | Social media, Text manual editing | By construction | 🟢 | https://github.com/stevejpapad/image-text-verification | ||
| CHASMA | 2024 | Various | EN | 2,015,488 | 🖼️ | (no evidence) | INC | 2 | 2: True, MC (miscaptioned: fake text) | Social media, News websites, Text-image auto-pairing | By construction | ⚙️ | https://github.com/stevejpapad/image-text-verification | ||
| CHASMA-D | 2024 | Various | EN | 291,782 | 🖼️ | (no evidence) | INC | 2 | 2: True, MC (miscaptioned: fake text) | Social media, News websites, Text-image auto-pairing | By construction | ⚙️ | https://github.com/stevejpapad/image-text-verification | ||
| MFD-Task1 | 2023 | 2022 Ukrainian-Russian war | IT | 1,795 | 🖼️ | (no evidence) | INC | 3 | 3: Misleading, Not Misleading, Unrelated | Social media, News websites | Crowdsourcing | 🅰️ | https://sites.google.com/unipi.it/multi-fake-detective | ||
| MFD-Task2 | 2023 | 2022 Ukrainian-Russian war | IT | 1,460 | 🖼️ | (no evidence) | FAC | 4 | 4: Certainly Fake, Probably Fake, Probably Real, Certainly Real | Social media, News websites | Crowdsourcing | 🅰️ | https://sites.google.com/unipi.it/multi-fake-detective | ||
| CLIP-NESt | 2023 | Various (incl. Politics, Environment, Law) | EN | 2,838,082 | 🖼️ | (no evidence) | INC | 3 | 3: True, OOC (pairing image and incongruous caption), NEI (manipulating entities in a true caption) | News websites, Text auto-tampering, Text-image auto-pairing | By construction | ⚙️ | https://github.com/stevejpapad/image-text-verification | ||
| COSMOS | 2023 | Various (incl. Politics, Health, Environment) | EN | 200,000 + 1,700 | 🖼️ | (no evidence) | INC, STA | 2 | 2: OOC, NOOC ONLY IN TEST SET TRAIN E VAL ARE WITHOUT LABELS | Social media, News websites | Human annotation | 💬 | https://github.com/shivangi-aneja/COSMOS/tree/main | ||
| Twitter-COMMs | 2022 | COVID19, Climate, Military Vehicles | EN | 2,468,592 | 🖼️ | (no evidence) | INC | 2 | 2: Pristine, Falsified | Social media | By construction | 🅰️ | https://github.com/GiscardBiamby/Twitter-COMMs | ||
| Evons | 2022 | 2016 USA Presidential Election | EN | 92,969 | 🖼️⁕ | (no evidence) | FAC | 2 | 2: Real, Fake | News websites | Website reputation | 🟢 | https://github.com/krstovski/evons | ||
| CovID I | 2022 | COVID19 | EN | 2,369 | 🖼️ | (no evidence) | FAC | 2 | 2: True, False | Social media, News websites | Human annotation, By construction | 🟢 | https://drive.google.com/file/d/1bjMrvPIgwAXt_nvtmP0vFqEqEtYq_YmS | ||
| CovID II | 2022 | COVID19 | EN | 2,474 | 🖼️ | (no evidence) | FAC | 2 | 2: True, False | Social media | Human annotation, By construction | 🟢 | https://drive.google.com/file/d/1ivBi9T0GoY3vkQiabWEQg6CnPSvkpAh7 | ||
| COVID5G | 2022 | COVID19 5G Conspiracy Theories | EN | 6,000 | 📹 | (no evidence) | FAC, STA | 3 or 5 or 6 | post 3: misinformation, countering, other video 6: explicit, implicit, neutral, ambivalent, others related to topic, others unrelated relationship 5: supports posts, related but not supporting post, contradiction, unrelated, support but ooc post-video 3: misinformation, countering, other | Social media | Human annotation | ❌ | |||
| NewsCLIPpings | 2021 | Various | EN | 988,283 | 🖼️ | (no evidence) | INC | 2 | 2: Pristine, Falsified | News websites, Text-image auto-pairing | By construction | 🟢 | https://huggingface.co/g-luo/news-clippings/tree/main/data | ||
| VOA-KG2txt | 2021 | Various | EN | 30,000 | 🖼️ | (no evidence) | FAC, EXP | 2 | 2: True, False | News websites, Text auto-tampering | By construction | 🟢 | https://github.com/yrf1/InfoSurgeon | ||
| Weibo C | 2021 | Various | ZH | 10,130 | 🖼️ | (no evidence) | FAC | 2 | 2: Real, Fake | Social media, News websites | FC websites | 🟢 | https://github.com/lumen2018/dataset | ||
| NeuralNews | 2020 | Various | EN | 128,000 | 🖼️ | (no evidence) | INC | 2 or 4 | 4: Real_Real, Real_Fake, Fake_Real, Fake_Fake | News websites, Text auto-generation, Text-image auto-pairing | By construction | 🟢 ⚙️ | https://cs-people.bu.edu/rxtan/projects/didan/ | ||
| TamperedNews | 2020 | Various | EN | 1,079,523 | 🖼️ | (no evidence) | INC | 2 | 2: positive, negative | News websites, Text auto-tampering, Text-image auto-pairing | By construction | 🅰️ | https://data.uni-hannover.de/dataset/tamperednews | ||
| News400 | 2020 | Various (incl. Politics, Economy, Sports) | DE | 6,360 | 🖼️ | (no evidence) | INC | 2 | 2: positive, negative | News websites, Text auto-tampering, Text-image auto-pairing | By construction | 🅰️ | https://data.uni-hannover.de/dataset/news400 | ||
| ReCOVery | 2020 | COVID19 | 40 languages | 2,029 + 140,820 | 🖼️ | (no evidence) | FAC | 2 | 2: Reliable, Unreliable | News websites | Website reputation | 🟢 🅰️ | https://github.com/apurvamulay/ReCOVery | ||
| r/Fakeddit | 2020 | Various | EN | 1,063,106 | 🖼️⁕ | (no evidence) | FAC, INC | 2 or 3 or 6 | 2: Real, Fake 3: Real, Fake, … something inbetween 6: True, Satire/Parody, Misleading Content, Imposter Content, False Connection, Manipulated Content | Social media | Website reputation | 🟢 | https://github.com/entitize/Fakeddit | ||
| FakeNewsNet | 2020 | Politics, Entertainment | EN | 23,196 | 🖼️ | (no evidence) | FAC | 2 | 2: Real, Fake | Social media, News websites | FC websites | 🅰️ | https://github.com/KaiDMML/FakeNewsNet | ||
| ExFaux | 2020 | Various | EN | 263 | 🖼️ | (no evidence) | INC | 2 or 5 | 2: True, Fake 5: True, Fake_img, Fake_text, Fake_img_and_text, Fake_True_img_and_text | Social media | Human annotation | ❌ | |||
| NewsBag | 2020 | Various | EN | 215,000 | 🖼️ | (no evidence) | FAC | 2 | 2: Real, Fake | News websites | Website reputation | ❌ | |||
| NewsBag++ | 2020 | Various | EN | 589,000 | 🖼️ | (no evidence) | FAC | 2 | 2: Real, Fake | News websites, Text auto-generation, Text-image auto-pairing | Website reputation, By construction | ❌ | |||
| NewsBag Test | 2020 | Various | EN | 29,000 | 🖼️ | (no evidence) | FAC | 2 | 2: Real, Fake | News websites | Website reputation | ❌ |
References
multimodal-afc-survey, GitHub Code Repository. URL: https://github.com/beatrice-portelli/multimodal-afc-survey
[Gallegos26] Gallegos Carvajal, I. M., Portelli, B., Zini, L., Baraldi, L., & Serra, G. (2026). An In-Depth Survey on Multimodal Automatic Fact-Checking Datasets. Multimedia Tools and Applications (under review)
[Kotonya20] Kotonya, N., & Toni, F. (2020, December). Explainable Automated Fact-Checking: A Survey. In Proceedings of the 28th International Conference on Computational Linguistics (pp. 5430-5443).
[Zeng21] Zeng, X., Abumansour, A. S., & Zubiaga, A. (2021). Automated fact‐checking: A survey. Language and Linguistics Compass, 15(10), e12438.
[Guo22] Guo, Z., Schlichtkrull, M., & Vlachos, A. (2022). A survey on automated fact-checking. Transactions of the association for computational linguistics, 10, 178-206.
[Hangloo22] Hangloo, S., & Arora, B. (2022). Combating multimodal fake news on social media: methods, datasets, and future perspective. Multimedia systems, 28(6), 2391-2422.
[Tufchi23] Tufchi, S., Yadav, A., & Ahmed, T. (2023). A comprehensive survey of multimodal fake news detection techniques: advances, challenges, and opportunities. International Journal of Multimedia Information Retrieval, 12(2), 28.
[Akhtar23] Akhtar, M., Schlichtkrull, M., Guo, Z., Cocarascu, O., Simperl, E., & Vlachos, A. (2023, December). Multimodal Automated Fact-Checking: A Survey. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 5430-5448).
[FakeClaim] Shahi, G. K., Jaiswal, A. K., & Mandl, T. (2024, March). Fakeclaim: a multiple platform-driven dataset for identification of fake news on 2023 Israel-hamas war. In European Conference on Information Retrieval (pp. 66-74). Cham: Springer Nature Switzerland.
[FineFake] Zhou, Z., Zhang, X., Zhang, L., Liu, J., Wang, S., Liu, Z., … & Yu, P. S. (2024). Finefake: A knowledge-enriched dataset for fine-grained multi-domain fake news detection. arXiv preprint arXiv:2404.01336.
[WarClaim] Shahi, G. K. (2024, May). Warclaim: a dataset for fake news on 2023 Israel–Hamas war. In Companion Publication of the 16th ACM Web Science Conference (pp. 19-21).
[RD-E] Yang, Z., Lin, J., Guo, Z., Li, Y., Li, X., Li, Q., & Liu, W. (2024). Towards rumor detection with multi-granularity evidences: A dataset and benchmark. IEEE Transactions on Knowledge and Data Engineering, 36(11), 7188-7200.
[MR2] Hu, X., Guo, Z., Chen, J., Wen, L., & Yu, P. S. (2023, July). Mr2: A benchmark for multimodal retrieval-augmented rumor detection in social media. In Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval (pp. 2901-2912).
[Factify2] Suryavardan, S., Mishra, S., Patwa, P., Chakraborty, M., Rani, A., Reganti, A., … & Kumar, S. (2023). Factify 2: A multimodal fake news and satire news dataset. arXiv preprint arXiv:2304.03897.
[MOCHEG] Yao, B. M., Shah, A., Sun, L., Cho, J. H., & Huang, L. (2023, July). End-to-end multimodal fact-checking and explanation generation: A challenging dataset and models. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2733-2743).
[OoCMMFC] Abdelnabi, S., Hasan, R., & Fritz, M. (2022). Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 14940-14949).
[STVD-FC] Rayar, F., Delalandre, M., & Le, V. H. (2022, September). A large-scale TV video and metadata database for French political content analysis and fact-checking. In Proceedings of the 19th International Conference on Content-based Multimedia Indexing (pp. 181-185).
[Factify] Mishra, S., Suryavardan, S., Bhaskar, A., Chopra, P., Reganti, A. N., Patwa, P., … & Ahuja, C. (2022, February). FACTIFY: A Multi-Modal Fact Verification Dataset. In DE-FACTIFY@ AAAI.
[MuMiN] Nielsen, D. S., & McConville, R. (2022, July). Mumin: A large-scale multilingual multimodal fact-checked misinformation social network dataset. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval (pp. 3141-3153).
[PolitifactSnopes] Vo, N., & Lee, K. (2020, November). Where are the facts? searching for fact-checked information to alleviate the spread of fake news. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 7717-7731).
[Fauxtography] Zlatkova, D., Nakov, P., & Koychev, I. (2019, November). Fact-checking meets fauxtography: Verifying claims about images. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 2099-2108).
[ChileCP] Molina, I., Keith, B., & Matus, M. (2025). A Multimodal Dataset of Fact-Checked News from Chile’s Constitutional Processes: Collection, Processing, and Analysis. Data, 10(2), 13.
[VERITE] [CHASMA] [CHASMA-D] Papadopoulos, S. I., Koutlis, C., Papadopoulos, S., & Petrantonakis, P. C. (2024). Verite: a robust benchmark for multimodal misinformation detection accounting for unimodal bias. International Journal of Multimedia Information Retrieval, 13(1), 4.
[MFD-Task1] [MFD-Task2] Bondielli, A., Dell’Oglio, P., Lenci, A., Marcelloni, F., Passaro, L. C., & Sabbatini, M. (2023). Multi-fake-detective at EVALITA 2023: Overview of the multimodal fake news detection and verification task.
[CLIP-NESt] Papadopoulos, S. I., Koutlis, C., Papadopoulos, S., & Petrantonakis, P. (2023, June). Synthetic misinformers: Generating and combating multimodal misinformation. In Proceedings of the 2nd ACM International Workshop on Multimedia AI against Disinformation (pp. 36-44).
[COSMOS] Aneja, S., Bregler, C., & Nießner, M. (2023, June). COSMOS: catching out-of-context image misuse using self-supervised learning. In Proceedings of the AAAI conference on artificial intelligence (Vol. 37, No. 12, pp. 14084-14092).
[Twitter-COMMs] Biamby, G., Luo, G., Darrell, T., & Rohrbach, A. (2022, July). Twitter-COMMs: Detecting climate, COVID, and military multimodal misinformation. In Proceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies (pp. 1530-1549).
[Evons] Krstovski, K., Ryu, A. S., & Kogut, B. (2022, October). Evons: A dataset for fake and real news virality analysis and prediction. In Proceedings of the 29th International Conference on Computational Linguistics (pp. 3589-3596).
[CovID I] [CovID II] Raj, C., & Meel, P. (2022). ARCNN framework for multimodal infodemic detection. Neural Networks, 146, 36-68.
[COVID5G] Micallef, N., Sandoval-Castañeda, M., Cohen, A., Ahamad, M., Kumar, S., & Memon, N. (2022, May). Cross-platform multimodal misinformation: Taxonomy, characteristics and detection for textual posts and videos. In Proceedings of the International AAAI Conference on Web and Social Media (Vol. 16, pp. 651-662).
[NewsCLIPpings] Luo, G., Darrell, T., & Rohrbach, A. (2021, November). Newsclippings: Automatic generation of out-of-context multimodal media. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 6801-6817).
[VOA-KG2txt] Fung, Y., Thomas, C., Reddy, R. G., Polisetty, S., Ji, H., Chang, S. F., … & Sil, A. (2021, August). Infosurgeon: Cross-media fine-grained information consistency checking for fake news detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 1683-1698).
[Weibo C] Song, C., Ning, N., Zhang, Y., & Wu, B. (2021). A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Information Processing & Management, 58(1), 102437.
[NeuralNews] Tan, R., Plummer, B., & Saenko, K. (2020, November). Detecting cross-modal inconsistency to defend against neural fake news. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 2081-2106).
[TamperedNews] [News400] Müller-Budack, E., Theiner, J., Diering, S., Idahl, M., & Ewerth, R. (2020, June). Multimodal analytics for real-world news using measures of cross-modal entity consistency. In Proceedings of the 2020 international conference on multimedia retrieval (pp. 16-25).
[ReCOVery] Zhou, X., Mulay, A., Ferrara, E., & Zafarani, R. (2020, October). Recovery: A multimodal repository for covid-19 news credibility research. In Proceedings of the 29th ACM international conference on information & knowledge management (pp. 3205-3212).
[r/Fakeddit] Nakamura, K., Levy, S., & Wang, W. Y. (2020, May). Fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. In Proceedings of the twelfth language resources and evaluation conference (pp. 6149-6157).
[FakeNewsNet] Shu, K., Mahudeswaran, D., Wang, S., Lee, D., & Liu, H. (2020). Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big data, 8(3), 171-188.
[ExFaux] Kou, Z., Zhang, D. Y., Shang, L., & Wang, D. (2020, December). Exfaux: A weakly supervised approach to explainable fauxtography detection. In 2020 IEEE international conference on big data (Big Data) (pp. 631-636). IEEE.
[NewsBag] [NewsBag++] [NewsBag Test] Jindal, S., Sood, R., Singh, R., Vatsa, M., & Chakraborty, T. (2020, February). Newsbag: A multimodal benchmark dataset for fake news detection. In CEUR Workshop Proc (Vol. 2560, No. 1, pp. 138-145).